A new paper and video demonstration have been published of a technique for rendering animated talking heads from very few still photos of a subject. According to the summary, “several recent works have shown how highly realistic human head images can be obtained by training convolutional neural networks to generate them. In order to create a personalized talking head model, these works require training on a large dataset of images of a single person. However, in many practical scenarios, such personalized talking head models need to be learned from a few image views of a person, potentially even a single image. Here, we present a system with such few-shot capability”. We, in this case, is Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, Victor Lempitsky from Samsung AI Lab. Watch a demonstration on YouTube and read the paper on Arxiv.org.
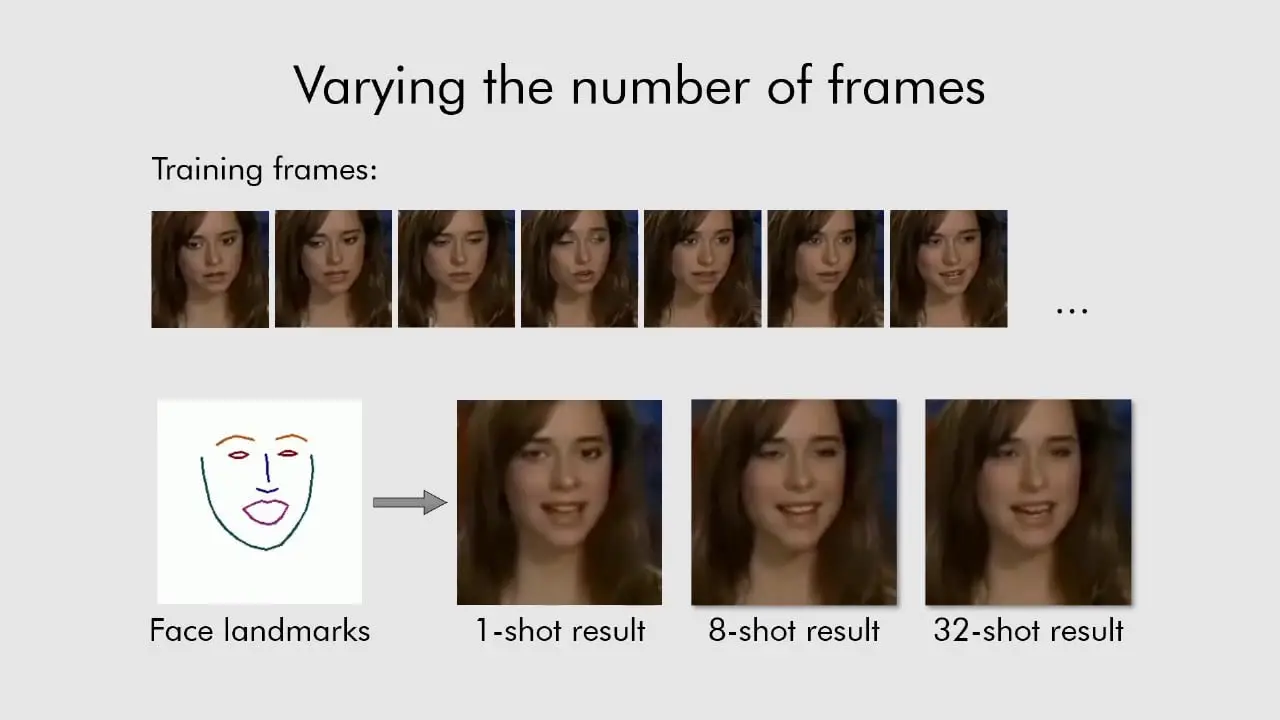
Few-shot adversarial learning of realistic neural talking head models
Related Posts







{kind=link}

CGPress is an independent news website built by and for CG artists. With more than 15 years in the business, we are one of the longest-running CG news organizations in the world. Our news reporting has gathered a reputation for credibility, independent coverage and focus on quality journalism. Our feature articles are known for their in-depth analyses and impact on the CG scene. “5 out of 5 artists recommend it.”
That’s some scary s**t, dude. A perfect tool to spread fake news.
This of course looks fake, but just from the small amount of input data used, it is crazy good. I can’t imagine how hard it will be to tell if something is fake or not in 10 years.
I can also see politicians and other well known people blaming the tech for things they’ve actually done/said on video in the past, and claiming it to be deepfake news. And their base/fans will believe them of course. Currently, there’s tell-tale signs that they are a deepfake. But to the majority of people out there who don’t know how the tech works, they’ll believe anything is or isn’t a deepfake depending on who is telling that it is or isn’t. People are just gullible. :/